Architecting the AstraZeneca vaccine booking site

A highly-scalable vaccine booking website in the cloud.
Introduction
In this blog post, I try to explore what it takes to build a highly scalable vaccine booking site using “boring” technologies and good old architecture patterns on Google Cloud. Notably, I will not be using DynamoDB or Bigtable or NoSQL databases of that sort. I think SQL can work here.
Disclaimer
I am obviously not privy to all the requirements and constraints of the VaksinCovid website team. Coming up with a blog post like this requires making assumptions. Failure happens to everybody in this industry and we just want to learn from failures and not bash people. There is always something to improve on. A lot of people bitching about the RM70 million but note that it is not for this booking system alone, it is for a whole suite of systems. In the enterprise contracting world, RM70 million is justifiable. Also, there are many ways to skin a cat, and this is no doubt just one of them, but with a focus on simplicity. I am also not affiliated with Google Cloud, but it is my favorite cloud :)
Cool? OK, read on.
Does this need to be solved?
First of all, it should be considered whether this problem needs to be solved. It is much simpler to put the AstraZenaca opt-in in the MySejahtera app, and not allow people to choose their dates. This to me is the most sensible option without going through the rabbit hole of a vaccine booking website. The MySejahtera analytics team can then process the data in their own sweet time, and even prioritize older folks from there. And people are generally OK with any date (because it’s a long-awaited vaccine), and most are able to take leave for this.
But sometimes your boss says, “Just do what I say”. If so, read on.
Problems with the site
So, the AstraZeneca debacle yesterday was highly distressing and ruined the public holiday for most of us. It is hard to believe that they actually managed to secure 500k bookings (1 mil doses available) when the endpoints were giving errors most of the time. Registration is closed (all spots purportedly taken), but it feels to me like it is just closed for maintenance while they fix the site or simply disburse the AZ vaccines separately.
The main issue with the site boils down to the endpoint for retrieving vaccine centers and booking times:
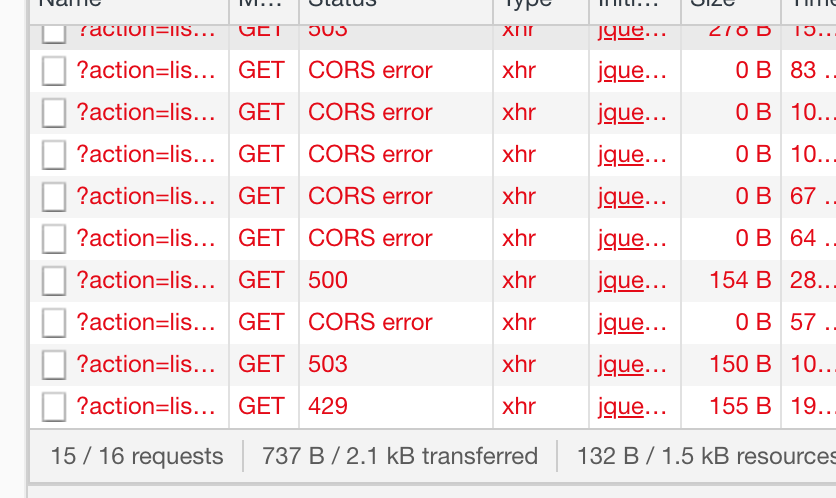
Error when retrieving the list of vaccine centers and booking times. You can repeatedly call this endpoint by hitting the State button.
You were given a form option for which State to choose from, and once you hit the State button, it tries to call an endpoint with ?action=listppv that does not include the State choice you selected.
At first glance, it looks like they made the noob CORS error, but it was more due to overloaded server’s inability to respond, and also Cloudflare helping to block further requests to the server because it was overloaded. Many have complained about Cloudflare on social media, but I’m going to just ignore Cloudflare altogether because it’s just a band-aid.
Quick UI Fixes
There are a few options for a quick fix, primarily on the frontend:
- Showing the user the error when the State button fails is the fastest quick win. Something like “Sorry, there was an error retrieving appointment locations and times. Please click here to try again.” shows respect to the user and communicates what is going on.
- Hide the vaccine location selection in part 2 of the form, forcing the user to Captcha first before being able to select the State button. The State button when clicked will send along the Captcha token to the backend for verification (Captchas expire after a short time, so this also protects against bots). This will give the server a much more breathing room from people spamming the State button.
- Disable the vaccine location button when clicked until a 200 result is returned. If a non-200 result is returned, re-enable the button again after a timeout of say 3 seconds. This will prevent people from being able to spam the State button and overwhelming the server.
Backend Architecture
UI fixes are nice, but the backend still needs to be handling a lot of calls. How many? If 1 million Malaysians are trying to capture 500k booking slots, then maybe the API needs to handle up to 100000 queries per second in the first minute? OK, maybe in actual it is a much lower number, 10000 qps? This suggests that the badly hit endpoint needs to be completely served from a cache layer, it cannot hit the database.
I would write the API application in Go. Go is highly scalable and low in memory consumption. And it is statically typed, meaning once it compiles, it generally just works, and you eliminite a lot of development mistakes out of the bat.
A. Endpoint to retrieve booking times
This is the endpoint that will take the most hit. It is crucial to serve this from a caching layer, i.e. Redis in our case. Memcache should also work just fine.
Hence we have the following setup:
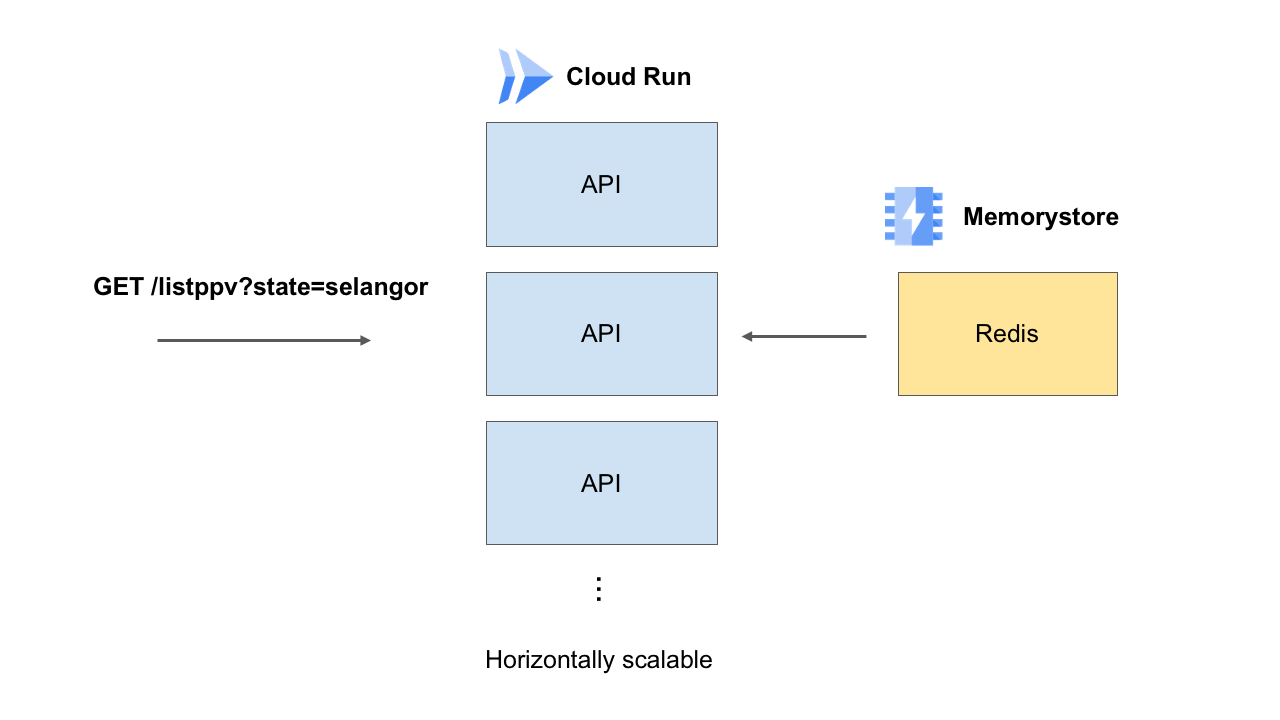
GET /listppv takes a State parameter that retrieves the booking times data from a Redis cache.
The API application resides in a container running in Cloud Run. The benefit of Cloud Run is that the container will be scaled horizontally as required by incoming traffic. There is an implicit load balancing that Cloud Run takes care for you. Alternatively you can also do VMs behind a load balancer in any cloud, but it is much faster to spin up containers than spinning up VMs. Anticipating high traffic, we can force Cloud Run to maintain a higher number of base container instances (because Cloud Run can scale to zero), and there can be no less than this number of container instances running.
The API endpoint should just make a cache selection from Redis based on the given State parameter. It just reads the data from Redis and returns it. That’s it.
We are making the assumption here that the data will be nicely sitting in the cache, provided for by someone else. We will figure out that part later.
B. Endpoint to handle booking submissions
If all goes well, the booking submission endpoint is also going to be hammered. Therefore, this endpoint must also not be doing anything much, i.e. it should not hit the database.
In my design, all this endpoint will do it simply publish the incoming appointment information into a Pub/Sub topic appointments-topic, and be done with it.
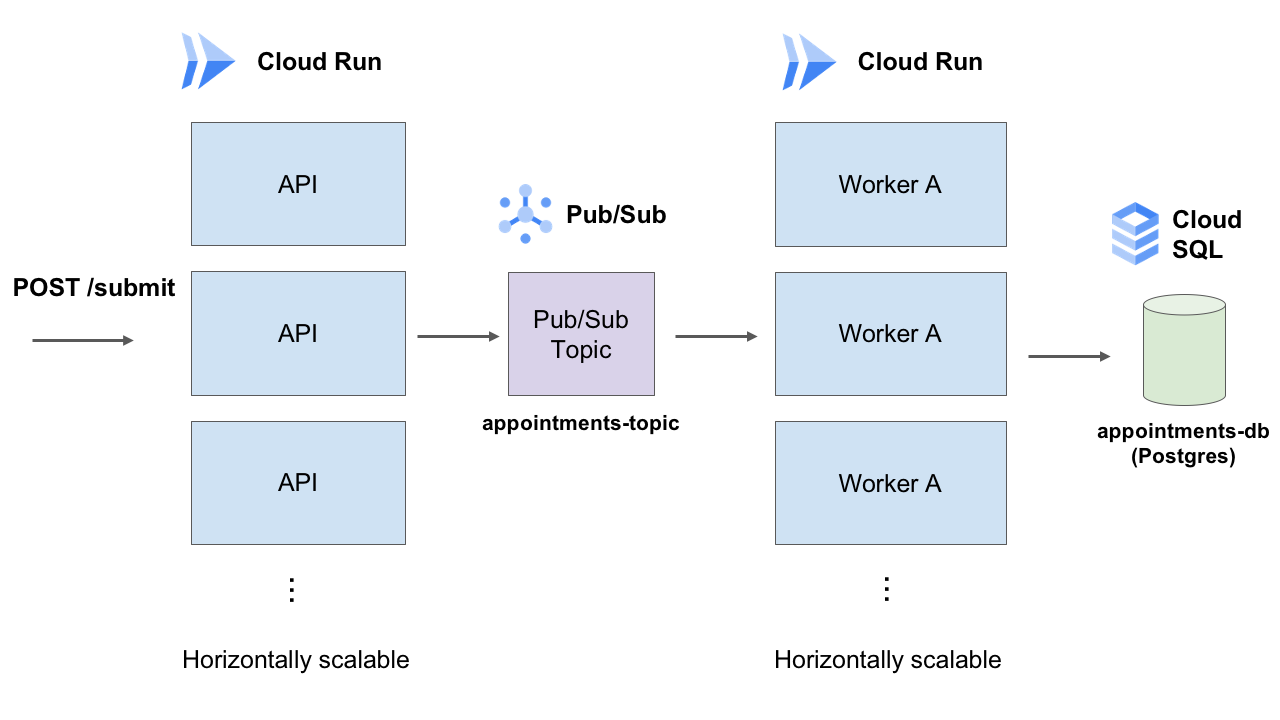
POST /submit takes a payload of the booking information, puts it into Pub/Sub, and returns. The payload is processed asynchronously by workers separately.
On the other end of this Pub/Sub topic are worker container instances running in Cloud Run (also horizontally scalable), processing the incoming booking information, and storing the booking information (INSERT) in the SQL database (Postgres in my case). It can optionally also send an email confirmation to the user (e.g. an API call to SendGrid), or (better) create another email-topic and workers to process email sending.
Lastly and importantly, in my design this worker does one more thing: Update a counter row in the database with a query like UPDATE mytable SET mycolumn = mycolumn + 1 that is immune to concurrency issues. In an earlier design I created a counter-topic with workers to do this, but simpler maybe is to just let this worker handle it, no need for so many sets of workers. Finally, it would be best to wrap these two queries (INSERT and UPDATE) in a DB transaction. In a failure scenario, Pub/Sub will retry calling the worker.
The counter rows will be used to update the Redis cache. That is what we explore next.
C. Updating booking times in the cache
Arguably this is the most critical part of the system, which will close the loop in our design.
Every 5-10 seconds, a separate single worker (Worker B) simply reads from the counter tables and updates the Redis cache for each State with the necessary data structure. The system is now complete.
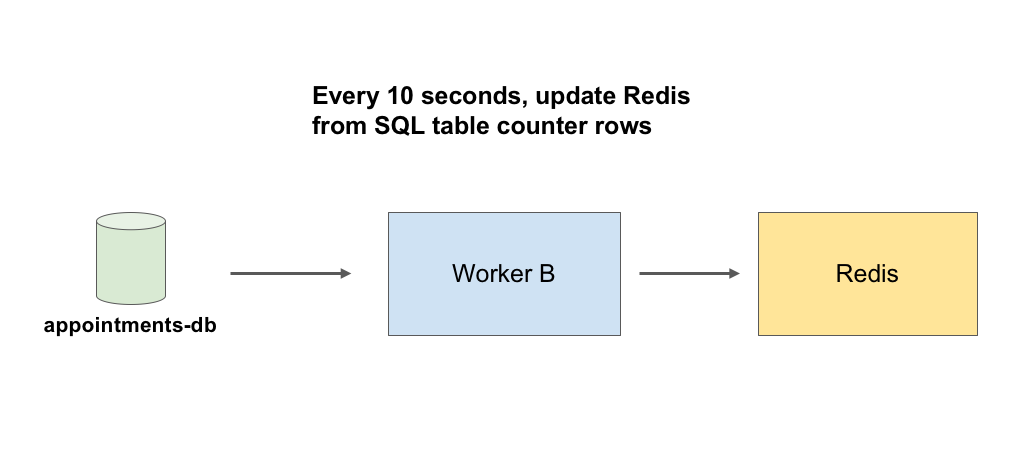
Worker B reads from the counter rows in the database and updates the Redis cache with available latest booking times (while disabling overbooked slots).
An assumption that I make here is that vaccine bookings, unlike cinema bookings, can handle a fair amount of overbooking. Hence my system assumes that some days can be slightly overbooked, and this is inevitable (in a highly scalable system) because there is a delay between when the user sees the form, and when the State list gets updated. I don’t really wish to go down the rabbit hole of websockets, which is another scalability headache and point of failure, and more complexity in the UI as well.
I have also omitted the database design here, but it is left as an exercise to the reader and from my experience won’t be a deal-breaker in our design. Obviously, correct database sizing is also crucial here.
Frontend Architecture
I would just deploy vaksincovid.com.my to Firebase Hosting as a static site. Firebase Hosting handles CDN for me, and is virtually infinitely scalable without any additional work on my part (just like this blog).
Pub/Sub Caveat
Pub/Sub is a publish at least once system, namely your system may end up processing the same message twice or more times. In practice, this is a rare occurence. You can choose to handle this by keeping track of the message IDs received in Redis, and do not process if you have seen it before.
Will this work?
In theory, yes. But in any system design, the ultimate test will be prototyping and deploying it in the real world. For something as high stakes as vaccine booking, a stress test with simulated dummy data and high qps would be crucial to test out the scalability of the system. However, there is always some element in stress testing that is not the same as a real production use case. Hence in the above we have designed it in such a way that we do not rely on anything that can cause bottlenecks, e.g. ensuring the API does not touch the database at all. With such a design we can have a lot more confidence in its scalability.
Is this the “best” design? No. But it tries to maintain system simplicity. The huge failing point may be huge overbookings at the start of the timeframe. Elrex Yeoh on Facebook suggested that people be put on waiting rooms/queues where they await their turn to make their booking (as in conventional booking systems). This is probably more robust (but more complexity), and is left as an exercise to the reader.
Again, the best solution is no solution. Just solve the problem via some other simple way like MySejahtera opt-in.
An Alternative Solution
Apart from the aforementioned MySejahtera opt-in solution, I thought of a much simpler solution that doesn’t deal with APIs, and is much simpler than my 3-step solution above.
Just serve the user with an application form (note: not a guaranteed booking) with all the dates and locations baked in (all slots open, no greyed out slots). Ask the user to select the location, then select 3 date preferences, one from each available week. Fine, if someone selects 3 consecutive Saturdays, then in that case we say “we will allocate for you if not available”, or provide a separate workflow for date reselection (better if date reselection can be done in MySejahtera). User submits the form, DONE. No listppv API, no Redis, no Pub/Sub (albeit the Pub/Sub intermediate layer would be recommended). Never mind if 2 million people submit and many receive rejections later. It would still be much more favorable than yesterday.
When a solution seems too complex (and we’re all lazy people), one should step back and re-examine the whole problem and try to think of the simplest possible solution. This date preferences solution would be an alternative viable solution that CANNOT fail.
Summary
In retrospect, at the beginning the AZ vaccine was not certain to be a hit. A non-scalable vaccine booking website was fine. But after the first round it was clear that the requirements have inadvertently changed. No one thought that a vaccine with higher blood clotting risk would have been a hit. Malaysians got too fed up with the pandemic and will just take whatever is on offer, especially one where you can easily fill up a form and get. I think this is the main reason why we ended up with this debacle. Requirements changing or not understood properly is a common cause of IT project failures.
I hope I have demonstrated that system design is more of an art than a science. Ask 1000 software engineers and solutions architects, and you will get back 1000 different designs (different data flows, different databases, different clouds, different programming languages, different UI, etc.). But most of these designs will share some general principles of best practices, and that is what you are looking for. There is no such thing as a perfect system, only “good enough”.


